bytedance/sdxl-lightning-4step
SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps
Model Inputs
Input prompt
Negative Input prompt
Width of output image. Recommended 1024 or 1280
Height of output image. Recommended 1024 or 1280
Number of images to output.
scheduler
Number of denoising steps. 4 for best results
Scale for classifier-free guidance
Random seed. Leave blank to randomize the seed
Disable safety checker for generated images
Result
Pricing
bytedance/
sdxl-lightning-4step
Pricing for Synexa AI models works differently from other providers. Instead of being billed by time, you are billed by input and output, making pricing more predictable.
For example, generating 100 images should cost around $0.10.
Check out our docs for more information about how per-request pricing works on Synexa.
| Provider | Price ($) | Saving (%) |
|---|---|---|
| Synexa | $0.0010 | - |
| replicate | $0.0020 | 50.0% |
Readme

SDXL-Lightning represents a groundbreaking advancement in text-to-image synthesis, offering exceptionally fast generation speeds. This model is capable of producing high-resolution 1024px images in just a few steps, making it ideal for applications requiring rapid image creation.
For in-depth technical information and research details, please refer to our paper: SDXL-Lightning: Progressive Adversarial Diffusion Distillation. We are releasing the SDXL-Lightning model as an open-source resource to foster further research and development in the community.
Model Overview
The SDXL-Lightning models are meticulously distilled from the robust stabilityai/stable-diffusion-xl-base-1.0 architecture. This repository provides a suite of checkpoints tailored for various inference step configurations, including 1-step, 2-step, 4-step, and 8-step models.
Experience remarkable image quality with the 2-step, 4-step, and 8-step models, designed for superior performance. The 1-step model is provided primarily for experimental purposes and may exhibit less stable generation quality.
We offer both full UNet and LoRA checkpoints to accommodate diverse usage scenarios and preferences.
Explore Demonstrations
Witness the capabilities of SDXL-Lightning through these impressive community-developed demonstrations:
- Comprehensive Configuration & Maximum Quality Generation: Demo
- Real-time Text-to-Image Generation (Lightning-Fast): Demo1, Demo2
- Comparative Analysis with Other Models: Link
Diffusers Usage Guide
To ensure optimal performance, it is crucial to utilize the checkpoint specifically designed for your intended inference step count.
1-Step UNet Checkpoint (Experimental)
Please note that the 1-step model is experimental and may produce results with lower quality and stability compared to the multi-step models. For enhanced image quality, we recommend utilizing the 2-step model.
The 1-step model employs "sample" prediction instead of "epsilon" prediction. Consequently, it is essential to configure the scheduler accordingly.
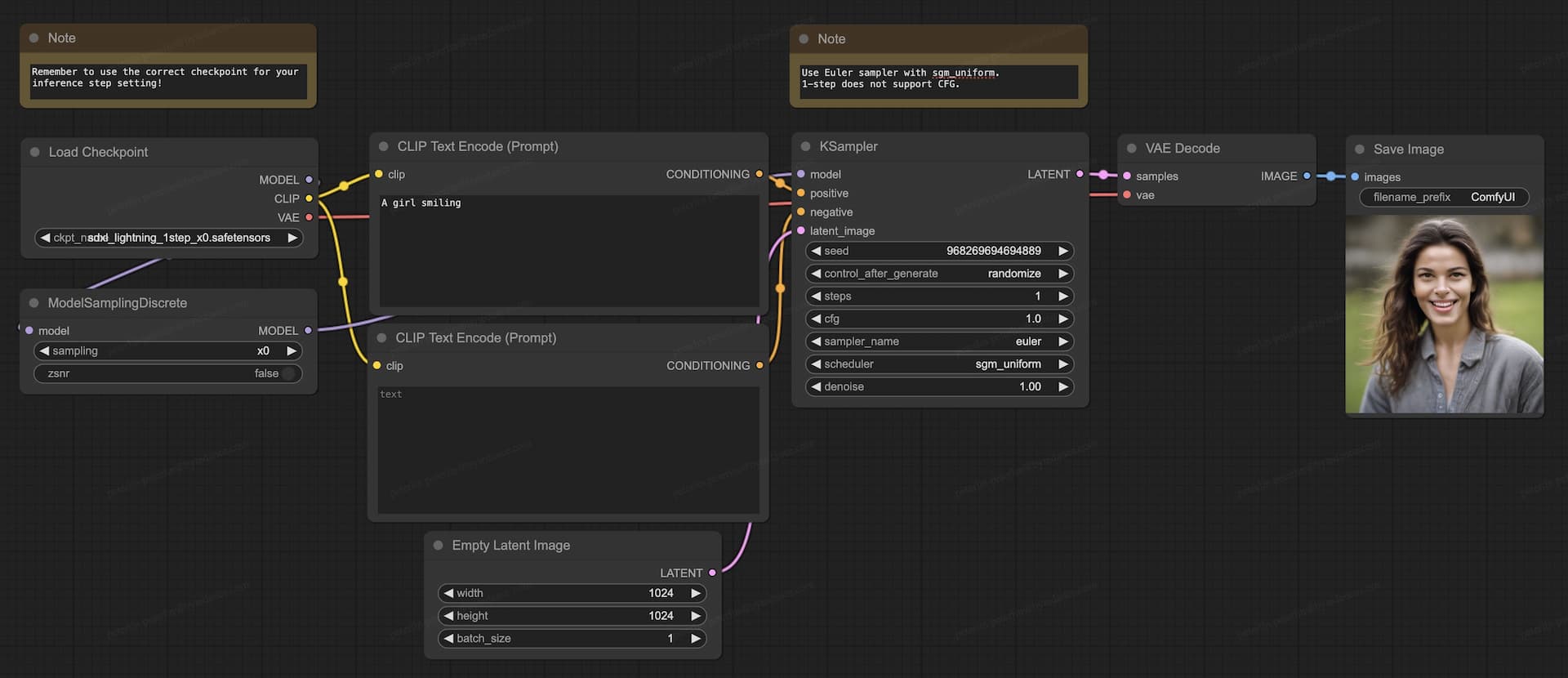
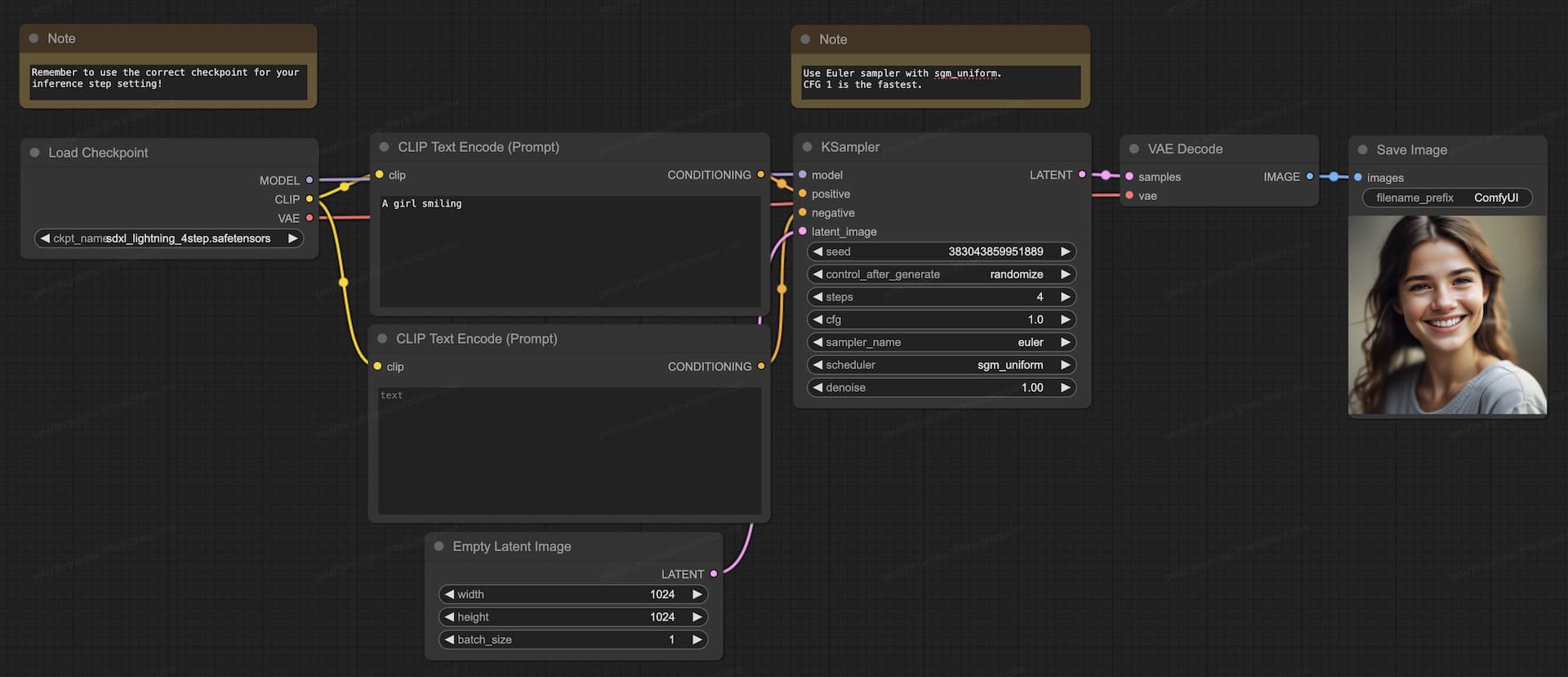
ComfyUI Usage Guide
For ComfyUI implementation, always select the appropriate checkpoint that corresponds to the desired number of inference steps. We recommend employing the Euler sampler in conjunction with the sgm_uniform scheduler for best results.
UNet Checkpoints (2-Step, 4-Step, 8-Step)
- Download the full checkpoint file (
sdxl_lightning_Nstep.safetensors) and place it in the/ComfyUI/models/checkpointsdirectory. - Download our comprehensive ComfyUI UNet workflow for seamless integration.
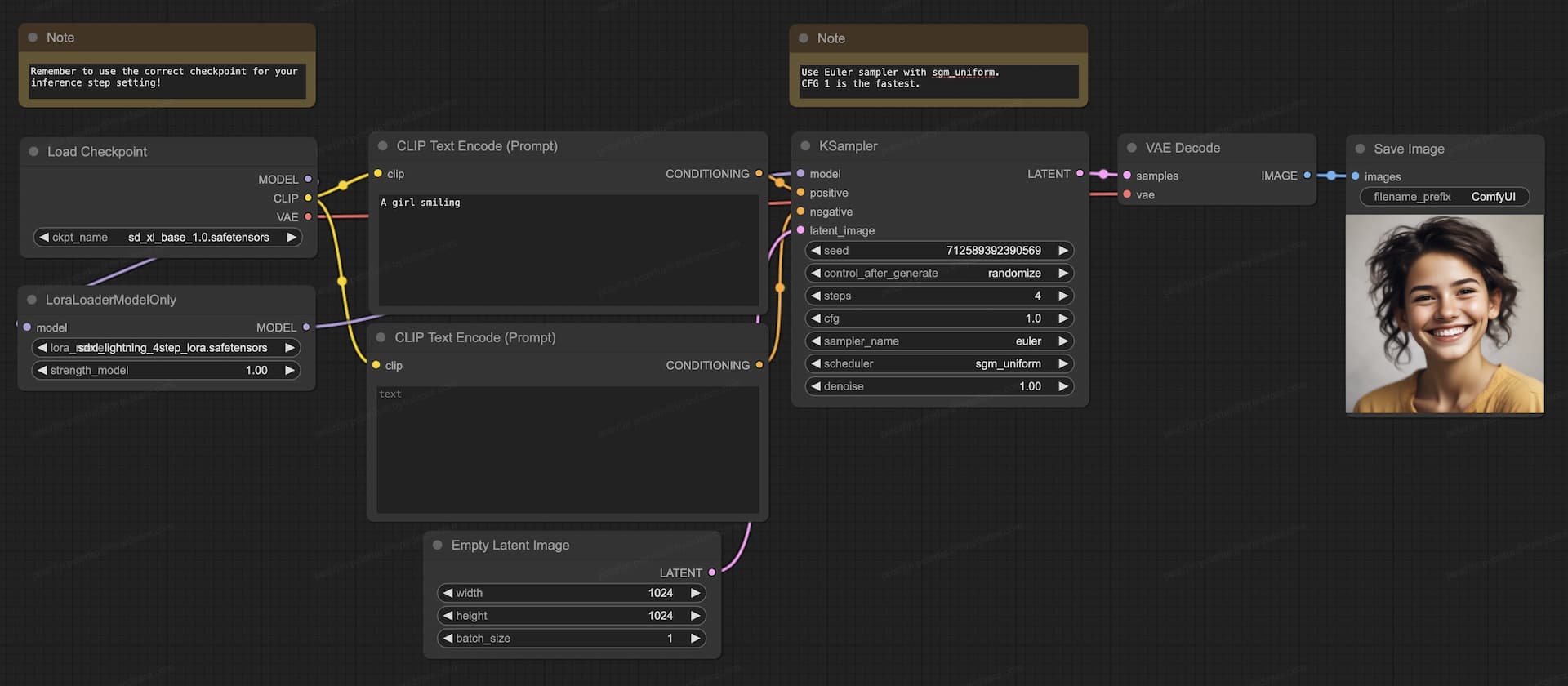
LoRA Checkpoints (2-Step, 4-Step, 8-Step)
- Ensure you have a compatible base model prepared within your ComfyUI environment.
- Download the LoRA checkpoint file (
sdxl_lightning_Nstep_lora.safetensors) and place it in the/ComfyUI/models/lorasdirectory. - Download our dedicated ComfyUI LoRA workflow for streamlined usage.
1-Step UNet Checkpoint (Experimental)
The 1-step model remains experimental and may exhibit reduced quality and stability. For improved results, consider using the 2-step model.
- Ensure your ComfyUI installation is updated to the latest version for optimal compatibility.
- Download the full 1-step checkpoint file (
sdxl_lightning_1step_x0.safetensors) and place it in the/ComfyUI/models/checkpointsdirectory. - Download our specific ComfyUI full 1-step workflow designed for the 1-step model.